miniAI
![]()
![]()
![]()

miniAI is an educational implementation of an artificial neural network built entirely from scratch in pure C, with no external machine learning library dependencies. The project demonstrates the fundamentals of deep learning through a complete feed-forward architecture, including forward propagation, backpropagation, L2 regularization, gradient clipping, and hyperparameter optimization.
Table of Contents
- Key Features
- Project Structure
- Compilation
- Static vs PNG Datasets
- Usage
- Command reference
- Technical Architecture
- Unit Tests
- Hyperparameter Configuration
- Implementation Details
- Debugging and Troubleshooting
- Educational Concepts
- Possible Extensions
- References and Resources
- Technical Notes
- Contributing
- License
- Author
- Acknowledgments
Key Features
Neural Network Architecture
- Multi-Layer Feed-Forward Network: Flexible architecture with configurable number of hidden layers.
- Activation Functions: ReLU for hidden layers, Softmax for output layer.
- Complete Backpropagation: Full backpropagation implementation with ReLU derivatives.
- L2 Regularization: Overfitting prevention through weight penalization.
- Gradient Clipping: Protection against exploding gradients.
- Xavier/He Initialization: Smart weight initialization for faster convergence.
Recognition Capabilities
1. Digit Recognition (0-9)
Static Dataset:
- 5×5 pixel grid (25 input features).
- 10 output classes.
- Fast in-memory training.
PNG Dataset:
- 8×8 pixel grid (64 input features).
- 10 output classes.
- Realistic image testing.
2. Alphanumeric Recognition (0-9, A-Z, a-z)
Static Dataset:
- 8×8 pixel grid (64 input features).
- 62 output classes.
- Fast training with hardcoded data.
PNG Dataset:
- 16×16 pixel grid (256 input features).
- 62 output classes.
- High-resolution character recognition.
3. Phrase Recognition
- Automatic character segmentation.
- Word space detection.
- PNG image processing.
- Full phrase support with alphanumeric characters.
Unified Command-Line Interface
- Single executable (
miniAI) with multiple commands. - train - Train models with automatic hyperparameter optimization.
- test - Test models on datasets or individual images.
- benchmark - Run hyperparameter grid search.
- recognize - Recognize phrases in images.
Memory Management
- Arena Allocator: Efficient and deterministic memory allocation system.
- Scratch Arena: Temporary recyclable memory between operations.
- Permanent Arena: Persistent memory for weights and model structures.
Memory Architecture

Image Processing
- PNG Loading: Native PNG image support via stb_image.
- Preprocessing: Grayscale conversion, resizing, and binarization.
- Otsu Threshold: Automatic adaptive binarization.
- Character Segmentation: Detection and extraction of individual characters in phrases.
Evaluation Tools
- Robustness Testing: Evaluation with artificial noise (salt & pepper).
- Confusion Matrix: Classification error visualization.
- Automatic Benchmarking: Grid search for hyperparameter optimization.
- Confidence Metrics: Output probabilities for each prediction.
Project Structure
miniAI/
├── headers/ # Organized headers by category
│ ├── cli/ # Command-line interface
│ │ ├── ArgParse.h # Argument parsing
│ │ └── Commands.h # Command execution
│ ├── core/ # Core neural network
│ │ ├── Arena.h # Memory management (arena allocator)
│ │ ├── Tensor.h # Matrix operations and activations
│ │ ├── Model.h # Neural model structure
│ │ ├── Grad.h # Gradients and derivatives
│ │ └── Glue.h # Training and inference API
│ ├── dataset/ # Dataset management
│ │ ├── Dataset.h # Unified dataset abstraction
│ │ └── TestUtils.h # Testing utilities
│ ├── image/ # Image processing
│ │ ├── ImageLoader.h # PNG image loading
│ │ ├── ImagePreprocess.h # Image preprocessing
│ │ └── Segmenter.h # Character segmentation
│ ├── tests/ # Unit test declarations
│ │ └── Tests.h # Test suite interface
│ └── utils/ # Utilities
│ ├── Random.h # Random seed utilities
│ └── Utils.h # Helper functions
│
├── src/ # Implementations (mirrors headers/)
│ ├── cli/ # CLI implementation
│ │ ├── ArgParse.c # Argument parsing
│ │ ├── Commands.c # Command dispatcher
│ │ └── commands/ # Command implementations
│ │ ├── Train.c # Training command
│ │ ├── Test.c # Testing command
│ │ ├── Benchmark.c # Benchmarking command
│ │ └── Recognize.c # Phrase recognition command
│ ├── core/ # Core implementations
│ │ ├── Arena.c # Arena allocator
│ │ ├── Tensor.c # Tensor operations
│ │ ├── Model.c # Model save/load
│ │ ├── Grad.c # Gradient calculation
│ │ └── Glue.c # Forward/backward pass
│ ├── dataset/ # Dataset implementations
│ │ ├── Dataset.c # Dataset abstraction
│ │ └── TestUtils.c # Testing utilities
│ ├── image/ # Image processing implementations
│ │ ├── ImageLoader.c # PNG loader
│ │ ├── ImagePreprocess.c # Preprocessing
│ │ └── Segmenter.c # Character segmentation
│ ├── tests/ # Unit test implementations
│ │ ├── Tests.c # Full test suite (Arena, Tensor, Grad, Shuffle, Model, Glue, ImagePreprocess)
│ │ └── TestConfig.c # g_trainConfig definition for test binary
│ └── utils/ # Utility implementations
│ ├── Random.c # Random seed
│ └── Utils.c # Shuffle, printDigit
│
├── IO/ # Input/Output and data
│ ├── MemoryDatasets.c # Static in-memory datasets
│ ├── MemoryDatasets.h # Dataset declarations
│ ├── images/ # PNG datasets
│ │ ├── digitsPNG/ # Digit images (8×8)
│ │ ├── alphanumericPNG/ # Alphanumeric images (16×16)
│ │ └── testPhrases/ # Test phrase images
│ ├── models/ # Trained models (.bin)
│ │ ├── digit_brain.bin # Static digits (5×5)
│ │ ├── digit_brain_png.bin # PNG digits (8×8)
│ │ ├── alpha_brain.bin # Static alpha (8×8)
│ │ └── alpha_brain_png.bin # PNG alpha (16×16)
│ ├── configs/ # Hyperparameter configs
│ │ ├── best_config_digits_static.txt
│ │ ├── best_config_digits_png.txt
│ │ ├── best_config_alpha_static.txt
│ │ └── best_config_alpha_png.txt
│ └── external/ # External libraries
│ └── stb_image.h # Header-only PNG loader
│
├── tools/ # Development tools
│ ├── generateChars.py # Generate character PNGs
│ └── generatePhrases.py # Generate phrase PNGs
│
├── AIHeader.h # Main unified header
├── miniAI.c # Main entry point
├── Makefile # Build system
└── README.md # This file
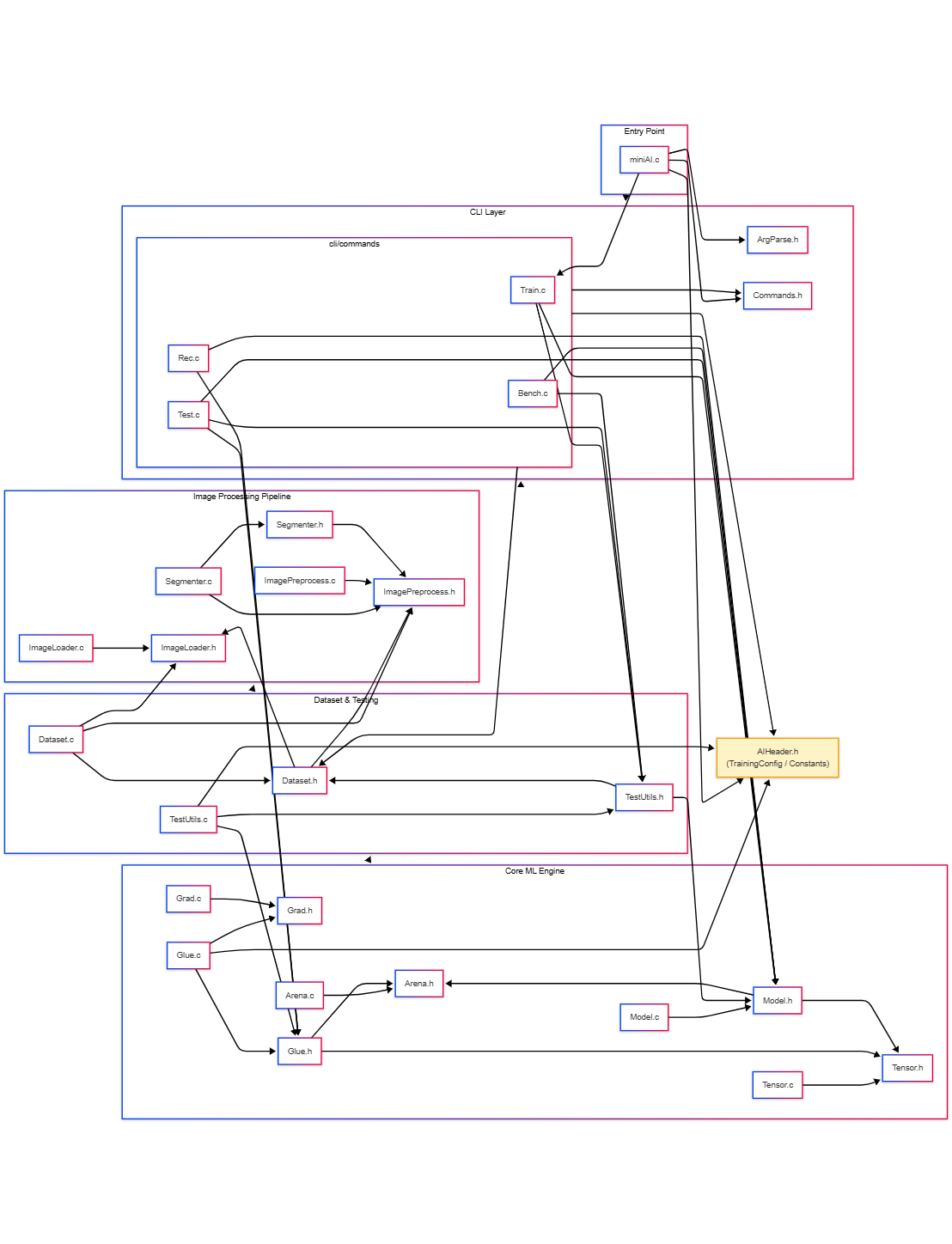
Module Dependencies
Module Dependencies
Compilation
Prerequisites
- C Compiler (GCC recommended, but you can change that in Makefile).
- Make.
- POSIX system (Linux, macOS, WSL).
- Standard math library (
libm). - Python 3 (for PNG generation scripts).
Build
# Build miniAI executable
make
# Clean build files
make clean
# Clean models only
make clean-models
# Clean configs only
make clean-configs
# Clean everything
make clean-all
# Complete rebuild
make rebuild
# View help
make help
Quick Start Examples
# Train with static dataset (fast, 5×5 digits)
make train-static-digits
# Train with PNG dataset (more realistic, 8×8 digits)
make train-png-digits
# Resume training from a saved model
make train-resume-digits
# Test static model
make test-static
# Test PNG model
make test-png
# Run benchmark
make benchmark-static
# Run unit tests
make unit-tests
# Show version
make version
Static vs PNG Datasets
miniAI currently supports two types of datasets, for flexibility and performance:
Static Datasets (In-Memory)
- Digits: 5×5 grid (25 inputs), hardcoded perfect samples.
- Alpha: 8×8 grid (64 inputs), hardcoded perfect samples.
- Advantages: Very fast training, no I/O overhead.
- Use case: Quick experiments, hyperparameter tuning.
- Models:
digit_brain.bin,alpha_brain.bin.
PNG Datasets (Realistic)
- Digits: 8×8 grid (64 inputs), PNG images.
- Alpha: 16×16 grid (256 inputs), high-res PNG images.
- Advantages: Realistic testing, external image support.
- Use case: Production models, phrase recognition.
- Models:
digit_brain_png.bin,alpha_brain_png.bin.
Dataset Types
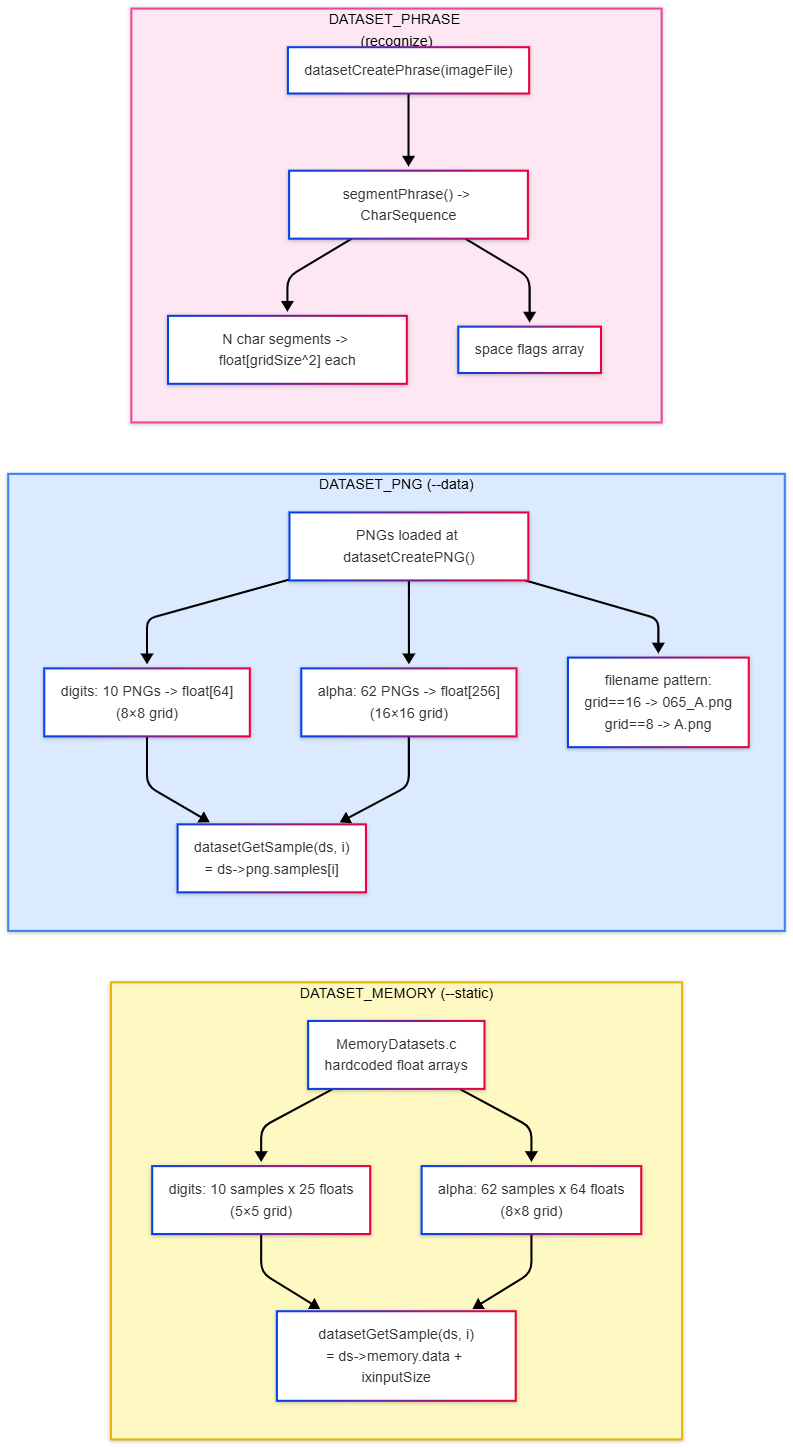
Important Notes
Models are NOT interchangeable! A model trained on static data cannot be used with PNG data (and vice-versa) due to different input dimensions!
Correct usage:
# Train static -> Test static
./miniAI train --dataset digits --static
./miniAI test [--model IO/models/digit_brain.bin] --dataset digits --static
# model can be inferred by dataset type.
# Train PNG → Test PNG
./miniAI train --dataset digits --data
./miniAI test --dataset digits --data
Incorrect usage (dimension mismatch):
# Don't mix static model with PNG dataset!
./miniAI test --model IO/models/digit_brain.bin --dataset digits --data
# Error: Layer 0 dimension mismatch! File: 1024x25, Expected: 1024x64
Usage
1. Training Models
Training Data Flow
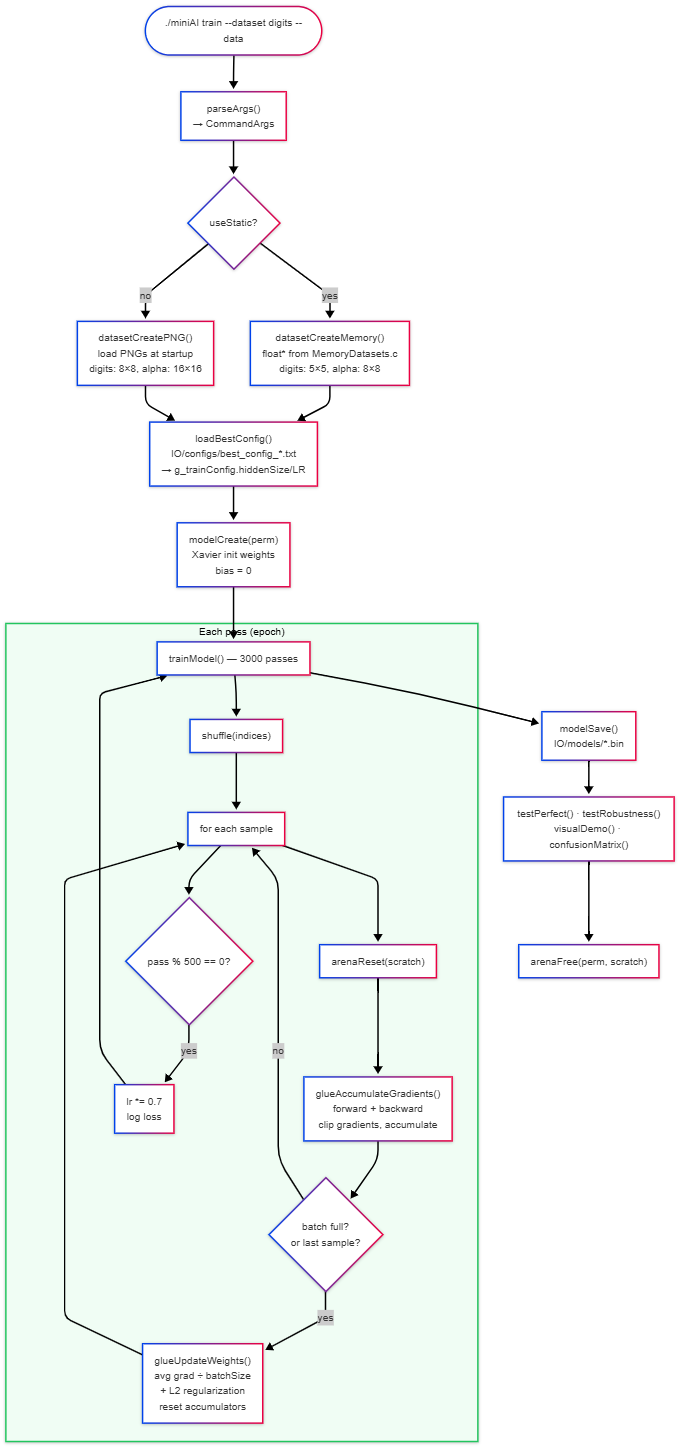
Static Dataset (Faster)
# Train digits (5×5, fast)
./miniAI train --dataset digits [--static]
# --static flag is by default in the operations it is defined. It is not mandatory passing it.
# Train static alphanumeric (8×8, fast)
./miniAI train [--dataset alpha]
# alphanumeric dataset is default, not mandatory passing it.
# so, ./miniAI train --dataset alpha --static
# = ./miniAI train
PNG Dataset (Realistic)
# Train digits (8×8, more realistic)
./miniAI train --dataset digits --data
# Train alphanumeric (16×16, more realistic)
./miniAI train --data
# Use custom PNG directory
./miniAI train --dataset digits --data /path/to/custom/digit/pngs
# so, if no path is provided to --data flag, it uses the default PNGs, at IO/images/.
Example Output:
=== TRAINING MODE ===
Dataset: PNG from IO/images/alphanumericPNG
Grid: 16x16 (256 inputs)
Classes: 62
Loaded 62/62 PNG samples
Loaded config: Hidden=128, LR=0.020
Model: 256 -> 128 -> 62
--- TRAINING PHASE (ALPHANUMERIC) ---
Pass 500 | Loss: 0.129139 | LR: 0.014000
Pass 1000 | Loss: 0.018894 | LR: 0.009800
Pass 1500 | Loss: 0.067296 | LR: 0.006860
Pass 2000 | Loss: 0.007140 | LR: 0.004802
Model saved to IO/models/alpha_brain_png.bin
Config saved: Hidden=128, LR=0.020
--- TEST 1: PERFECT SAMPLES ---
...
Accuracy: 62/62 (100.00%)
--- TEST 2: STRESS TEST (SALT & PEPPER) ---
...
Robustness Score (2-pixel noise): 100.00%
2. Testing Models
Test on Dataset
# Test static model on static dataset
./miniAI test --dataset digits --static
# Test PNG model on PNG dataset
./miniAI test --dataset digits --data
# Use custom dataset (no guarantee recognition will be good...)
./miniAI test --dataset digits --data /custom/path
Test on Single Image
# Test with single image (PNG mode automatic!):
./miniAI test --dataset digits --image test.png
# The system automatically:
# 1. Uses PNG mode when --image is provided.
# 2. Loads correct config (hidden size, learning rate).
# 3. Shows top-5 predictions with confidence.
Example Output:
=== TESTING MODE ===
Testing single image: test.png
Loaded config: Hidden=128, LR=0.020
Model: 256 -> 128 -> 62
Loading model from IO/models/alpha_brain_png.bin
Prediction: 'A' (Confidence: 99.23%)
Top 5 predictions:
1. 'A' - 99.23%
2. 'R' - 0.45%
3. 'H' - 0.18%
4. 'N' - 0.09%
5. 'M' - 0.03%
3. Phrase Recognition
# Recognize alphanumeric phrase (default)
./miniAI recognize --image phrase.png
# Recognize digits only
./miniAI recognize --model IO/models/digit_brain_png.bin [or: --dataset digits] --image numbers.png
# passing either model or dataset will infer that digits are being worked on.
Example Output:
=== PHRASE RECOGNITION MODE ===
Loading and segmenting phrase from: phrase.png
Segmented 10 characters
Grid: 16x16 (256 inputs per character)
Loaded config: Hidden=128, LR=0.020
Model: 256 -> 128 -> 62
========================================
RECOGNIZED PHRASE
========================================
"HELLO WORLD"
--- Character Details ---
Pos | Char | Confidence
----|------|------------
0 | H | 98.45%
1 | E | 99.12%
2 | L | 97.89%
3 | L | 98.23%
4 | O | 99.56%
5 | | (space)
6 | W | 98.91%
7 | O | 99.34%
8 | R | 97.67%
9 | L | 98.45%
10 | D | 99.01%
4. Hyperparameter Benchmarking
The system includes automatic grid search for optimal hyperparameters (benchmarking):
# Benchmark static dataset
./miniAI benchmark --dataset digits --static --reps 3
# Benchmark PNG dataset
./miniAI benchmark --dataset digits --data --reps 5
Example Output:
=== BENCHMARK MODE ===
Dataset: PNG from IO/images/digitsPNG
Grid: 8x8 (64 inputs)
Classes: 10
Repetitions: 3
--- SCIENTIFIC AI BENCHMARK (N=3) ---
Hidden | LR | Avg Score | Std Dev | Status
-------|-------|-------------|-----------|--------
16 | 0.001 | 85.23% | 2.45 |
16 | 0.005 | 92.67% | 1.89 | STABLE
16 | 0.008 | 94.12% | 3.21 | UNSTABLE
32 | 0.005 | 95.34% | 1.67 | STABLE
64 | 0.005 | 97.12% | 1.34 | STABLE
128 | 0.005 | 98.45% | 1.23 | STABLE
256 | 0.008 | 98.23% | 2.89 | UNSTABLE
512 | 0.005 | 98.67% | 1.45 | STABLE
WINNER: Hidden=512, LR=0.005 (Avg: 98.67%)
Config saved to IO/configs/best_config_digits_png.txt
Benchmark complete!
Note: simplified output. It tests every hidden size in {16, 32, 64, 128, 256, 512, 1024} for every learning rate in {0.001f, 0.005f, 0.008f, 0.01f, 0.015f, 0.02f}.
5. Complete Workflow Examples
Static Workflow (Fast Development)
# 1. Train
./miniAI train --dataset digits --static
# 2. Test
./miniAI test --dataset digits --static
# 3. Benchmark
./miniAI benchmark --dataset digits --static --reps 3
# 4. Test again with best hyperparameters
./miniAI test --dataset digits --static
PNG Workflow (More Realistic Testing)
# 1. Train
./miniAI train --dataset digits --data
# 2. Test on dataset
./miniAI test --dataset digits --data
# 3. Test on images
./miniAI test --image test1.png
./miniAI test --image test2.png
# 4. Benchmark
./miniAI benchmark --dataset digits --data --reps 5
# 5. Test again (on dataset or on images)
Phrase Recognition Workflow
# 1. Train PNG alpha model (or digit, if you want)
./miniAI train --dataset alpha --data
# 2. Recognize phrases
./miniAI recognize --image phrase1.png
./miniAI recognize --image phrase2.png
Docker
# Use without installing anything.
docker pull nelsonramosua/miniai:latest
# Treinar
docker run --rm -v $(pwd)/IO:/app/IO nelsonramosua/miniai train --dataset digits --static
# Ajuda
docker run --rm nelsonramosua/miniai help
Command Reference
Global Options
--dataset <type> Dataset type: digits, alpha (default: alpha)
--data [path] Use PNG dataset (optional path, defaults to IO/images/)
--static Use static in-memory dataset
--model <path> Path to model file (optional, can be inferred)
--image <path> Path to image file
--grid <size> Grid size: 5, 8, or 16 (default: auto)
--reps <n> Benchmark repetitions (default: 3)
--load Load existing model instead of training
--resume Load existing model and continue training
--seed <n> Fixed random seed for reproducibility (default: random)
--verbose, -v Verbose output (loss every 100 passes, hyperparameter summary)
Commands
train
Train a new model or continue training existing one.
./miniAI train --dataset <digits|alpha> [--static|--data [path]] [--load]
test
Test model on dataset or single image.
# Test on dataset
./miniAI test [--model <path>] --dataset <type> [--static|--data [path]]
# Test on image (PNG mode automatic)
./miniAI test [--model <path>] --image <path>
benchmark
Run hyperparameter grid search.
./miniAI benchmark --dataset <type> [--static|--data [path]] [--reps <n>]
recognize
Recognize phrase in image.
./miniAI recognize [--dataset <type>] --image <path>
help
Show help message.
./miniAI help
version
Show version string (also available as --version or -V).
./miniAI version
./miniAI --version
Unit Tests
miniAI includes a standalone unit test binary that verifies the correctness of all core components in isolation.
make unit-tests
The suite currently covers 7 modules with over 120 individual assertions:
| Suite | What is tested |
|---|---|
| Arena | Init, 8-byte alignment, zero-init, overflow protection, reset, two independent arenas |
| Tensor | tensorDot (known values, identity matrix), tensorAdd (commutativity), tensorSigmoid (symmetry, monotonicity), tensorSoftmax (sum=1, ordering, uniform input, numeric stability), tensorReLU, tensorFillXavier (range, mean, variance) |
| Grad | sigmoidDerivative (value at 0, saturation, symmetry, non-negativity, peak), tensorSigmoidPrime (element-wise match), tensorReLUDerivative (threshold at 0, upstream scaling) |
| Shuffle | Element integrity, no duplicates, length-0/1 edge cases, statistical non-identity |
| Model | Layer shape and count, zero-initialised gradients, Xavier weights, save/load bit-identical round-trip, architecture mismatch detection, missing file detection |
| Glue | Forward pass shape and finiteness, gluePredict valid index and confidence range, glueComputeLoss positive and finite, backprop direction (loss decreases), convergence to correct label, correct-label loss < wrong-label loss, numeric stability across 10 random trials |
| ImagePreprocess | rgbToGray ITU-R 601 coefficients (red≈76, green≈149, blue≈29), channel ordering, monotonicity; calculateOtsuThreshold bimodal, uniform, two-cluster, binary inputs |
The test binary compiles only core, image, and utility objects — it never links dataset, CLI, or miniAI.o. This guarantees no accidental contamination between the test binary and the main executable.
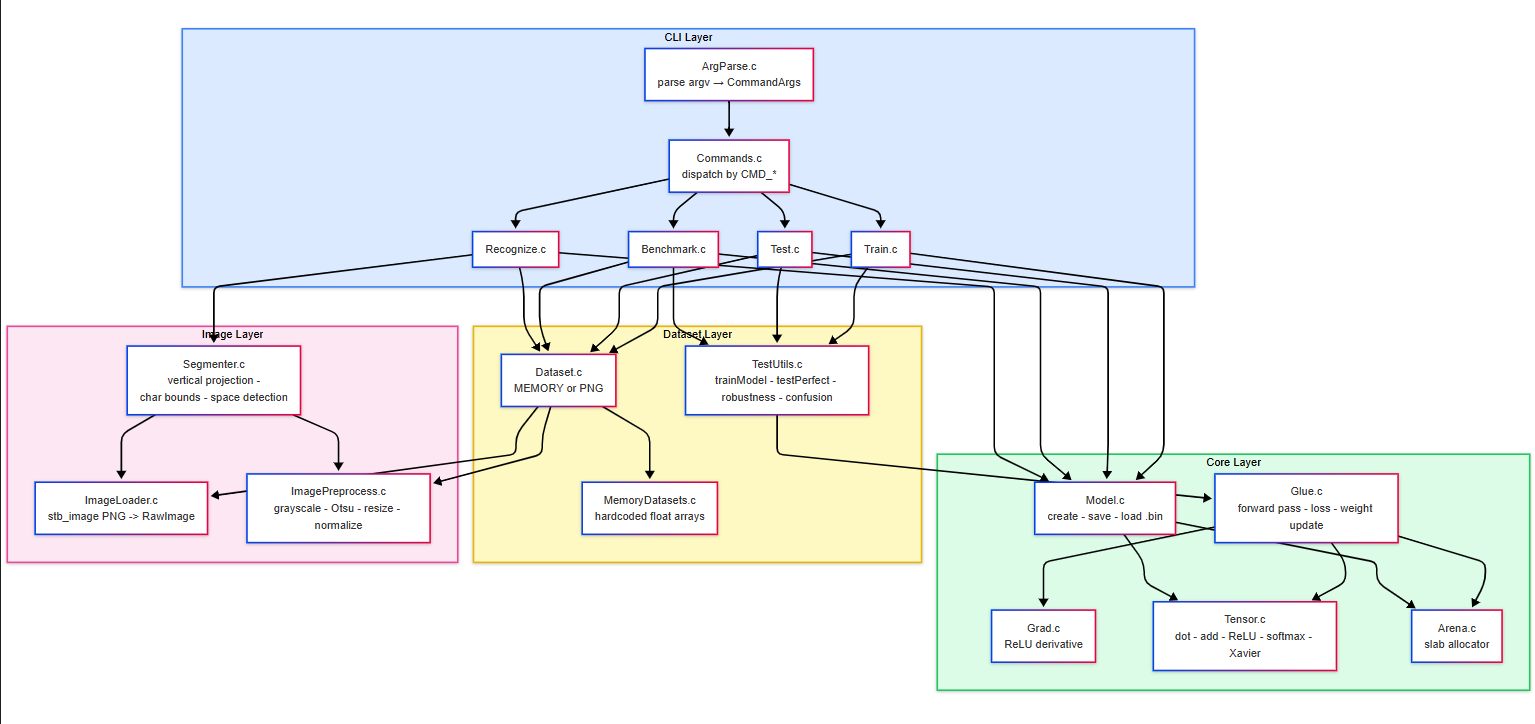
Technical Architecture
System Architecture
System Architecture
Tensor Structure
typedef struct {
int rows; // Number of rows
int cols; // Number of columns
float *data; // Data in row-major! format
} Tensor;
Layer Structure
typedef struct {
Tensor *w; // Weights
Tensor *b; // Bias
Tensor *z; // Pre-activation (cache)
Tensor *a; // Post-activation (cache)
Tensor *gradW; // Accumulated weight gradients
Tensor *gradB; // Accumulated bias gradients
} Layer;
Model Structure
typedef struct {
Layer *layers; // Array of layers
int count; // Number of layers
} Model;
Forward Propagation
For each layer i:
- Linear:
z[i] = W[i] * a[i-1] + b[i] - Activation:
- Hidden layers:
a[i] = ReLU(z[i]) - Output layer: Raw z[i] passed directly to the objective function (Softmax is applied during loss calculation).
- Hidden layers:
// Simplified forward pass
Tensor* glueForward(Model *m, Tensor *input, Arena *scratch) {
Tensor *currentInput = input;
for (int i = 0; i < m->count; i++) {
// z = W × input + b
tensorDot(m->layers[i].z, m->layers[i].w, currentInput);
tensorAdd(m->layers[i].z, m->layers[i].z, m->layers[i].b);
// Apply activation
if (i < m->count - 1) {
tensorReLU(m->layers[i].a, m->layers[i].z); // Hidden
} else {
// Output (softmax applied externally)
for(int j = 0; j < m->layers[i].z->rows; j++)
m->layers[i].a->data[j] = m->layers[i].z->data[j];
}
currentInput = m->layers[i].a;
}
return currentInput;
}
Forward Propagation Dataflow
Forward Pass
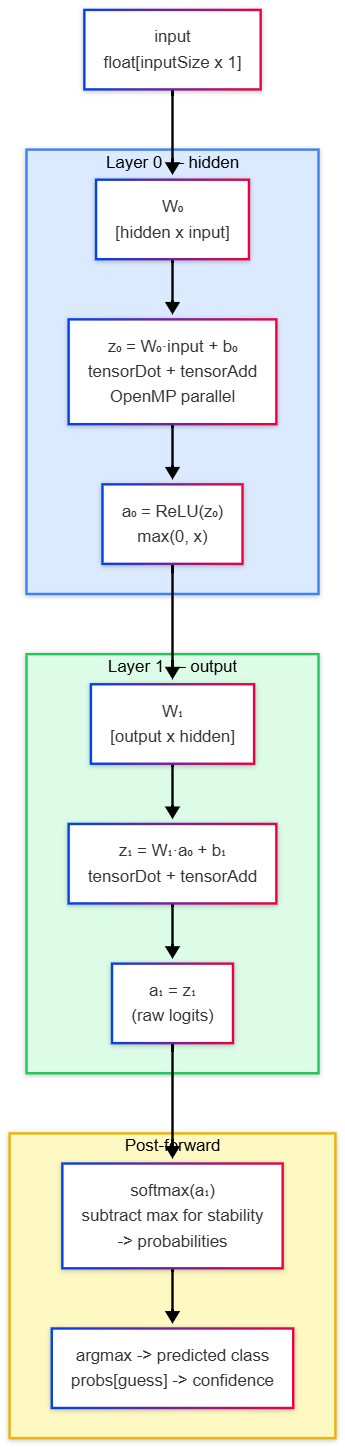
Backpropagation
The implemented backpropagation algorithm includes:
- Loss Function: Cross-Entropy with Softmax
L = -log(p_correct) - Output Gradient (Softmax + Cross-Entropy):
delta_output = p - targetwhere
targetis one-hot encoded - Weight Update with L2 regularization:
grad(W) = delta * a_prev + lambda × W W <- W - lr * clip(grad(W)) - Bias Update:
b <- b - lr * delta - Error Propagation (ReLU derivative):
delta_prev = (W^T * delta_current) .* ReLU'(z_prev)where
.*is element-wise multiplication
Backward Propagation Dataflow, on Layer i
Backward Pass on Layer i
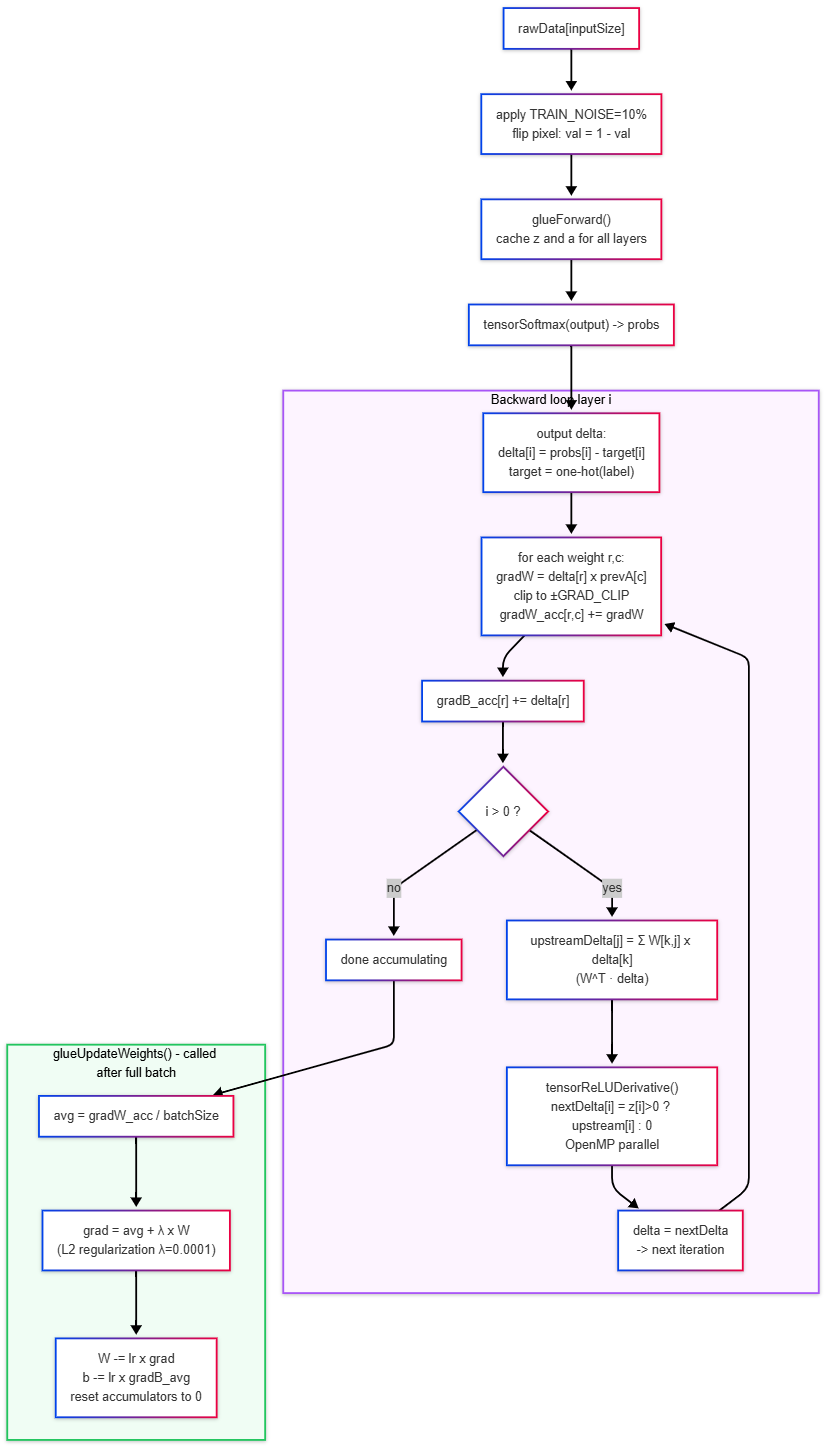
Activation Functions
ReLU (Rectified Linear Unit)
float relu(float x) {
return x > 0 ? x : 0;
}
// Derivative
float relu_derivative(float x) {
return x > 0 ? 1.0f : 0.0f;
}
Softmax
void tensorSoftmax(Tensor *out, Tensor *in) {
float max = in->data[0];
for (int i = 1; i < in->rows; i++) {
if (in->data[i] > max) max = in->data[i];
}
float sum = 0;
for (int i = 0; i < in->rows; i++) {
out->data[i] = expf(in->data[i] - max); // Numerical stability
sum += out->data[i];
}
for (int i = 0; i < in->rows; i++) {
out->data[i] /= sum;
}
}
Hyperparameter Configuration
Main Parameters (AIHeader.h)
// Network Architecture
#define DEFAULT_HIDDEN 512 // Hidden layer neurons
#define NUM_DIMS 3 // Number of dimensions [input, hidden, output]
// Training Parameters
#define DEFAULT_LR 0.02f // Initial learning rate
#define LAMBDA 0.0001f // L2 regularization factor
#define GRAD_CLIP 5.0f // Gradient clipping threshold
#define TRAIN_NOISE 0.10f // Pixel flip probability
// Training Configuration
#define TOTAL_PASSES 3000 // Number of epochs
#define DECAY_STEP 500 // Steps for LR decay
#define DECAY_RATE 0.7f // LR decay factor
#define BATCH_SIZE 32 // mini-batch size
// Testing
#define STRESS_TRIALS 1000 // Robustness tests
#define STRESS_NOISE 2 // Noisy pixels
#define CONFUSION_TESTS 500 // Confusion matrix tests
Dynamic Configuration
The system supports runtime configuration overrides (via benchmarking) through TrainingConfig, passed by config files:
typedef struct {
int hiddenSize; // Hidden layer size.
float learningRate; // Learning rate.
int benchmarkReps; // Benchmark repetitions.
int verbose; // 0 = normal output, 1 = loss every 100 passes.
int seed; // 0 = random seed, >0 = fixed reproducible seed.
} TrainingConfig;
Config File Format (IO/configs/best_config_*.txt):
128
0.020000
Line 1: Hidden size
Line 2: Learning rate
The system automatically:
- Saves best config after benchmarking
- Loads config before testing/recognition, etc.
- Ensures model dimensions match config
Implementation Details
Arena Allocator
The system uses a custom arena allocator for efficient memory management (src/core/Arena.c). It is designed for maximum performance through linear allocations and complete resets between inference/training steps.
typedef struct {
size_t capacity; // Total capacity.
size_t used; // Bytes used.
uint8_t *buffer; // Memory buffer.
} Arena;
// Creation
Arena *arena = arenaInit(8 * MB);
// Allocation (no individual free)
float *data = (float*)arenaAlloc(arena, sizeof(float) * size);
// Reset (resets allocation pointer to 0, "freeing" everything instantly)
arenaReset(arena);
// Destruction
arenaFree(arena);
Advantages:
- Extremely fast allocation (just pointer arithmetic).
- No metadata overhead per allocation.
- No fragmentation.
- Frees everything at once (ideal for batch operations).
Model Serialization
Models can be saved and loaded in binary format:
// Save model
modelSave(model, "IO/models/digit_brain.bin");
// Load model
Model *model = modelCreate(arena, dims, NUM_DIMS);
modelLoad(model, "IO/models/digit_brain.bin");
Binary File Format:
[int32] count - Number of layers
[int32] rows[0] - Layer 0 dimensions
[int32] cols[0]
...
[int32] rows[n-1] - Layer n-1 dimensions
[int32] cols[n-1]
[float32[]] weights[0] - Layer 0 weights
[float32[]] bias[0] - Layer 0 bias
...
[float32[]] weights[n-1] - Layer n-1 weights
[float32[]] bias[n-1] - Layer n-1 bias
Image Processing
Preprocessing Pipeline
- Loading: PNG → RawImage (via stb_image, see Acknowledgments).
- Conversion: RGB → Grayscale (luminance).
- Binarization: Automatic Otsu threshold.
- Resizing: Resize to target grid.
- Normalization: [0, 255] → [0.0, 1.0].
typedef struct {
int targetSize; // Grid size (8 for 8x8).
float threshold; // Binarization threshold.
int invertColors; // 1 = invert colors.
} PreprocessConfig;
PreprocessConfig cfg = {
.targetSize = 8,
.threshold = 0.5f,
.invertColors = 0
};
float *processed = imagePreprocess(rawImage, cfg);
Phrase Segmentation
Automatic character segmentation algorithm:
typedef struct {
float **chars; // Character array.
int count; // Number of characters.
int capacity; // Allocated capacity.
int charSize; // Size of each character.
} CharSequence;
SegmenterConfig cfg = defaultSegmenterConfig(16);
CharSequence *seq = segmentPhrase(image, cfg);
Segmentation Algorithm:
- Binarize image.
- Horizontal projection to detect text line.
- Vertical projection to detect character columns.
- Bounding box extraction with Otsu threshold.
- Resizing to uniform grid.
- Space detection (gaps larger than threshold).
Phrase Recognition Dataflow
Phrase Recognition Flow
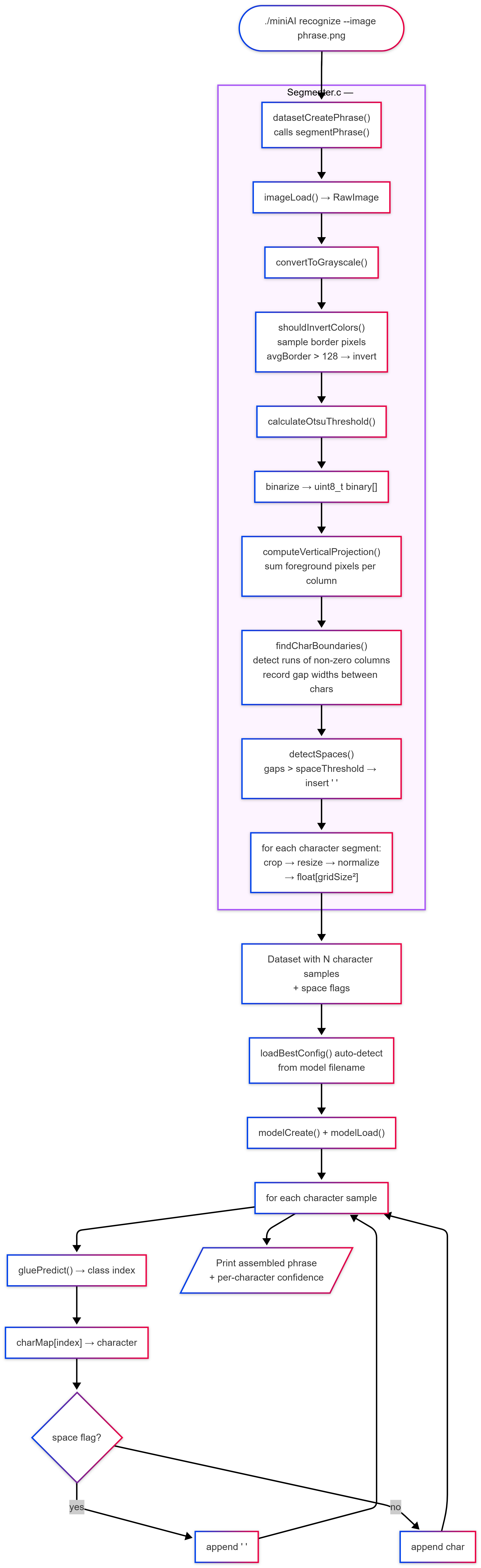
Multi-threading (OpenMP)
To ensure this pure-C implementation runs fast on the CPU, heavily nested loops (like matrix dot products and derivative mapping) are parallelized with OpenMP pragmas.
#pragma omp parallel for schedule(static)
for (int i = 0; i < a->rows; i++) {
// Math operations distributed across CPU cores...
}
Debugging and Troubleshooting
Common Issues
1. Dimension Mismatch Error
Error: Layer 0 dimension mismatch! File: 128x64, Expected: 512x64
Causes:
- Using static model with PNG dataset (or vice-versa).
- Model trained with different hidden size than current config.
Solutions:
# Make sure model type matches dataset type
# Static model -> Static dataset
./miniAI test --model IO/models/digit_brain.bin --dataset digits --static
# PNG model -> PNG dataset
./miniAI test --model IO/models/digit_brain_png.bin --dataset digits --data
# Or retrain with current config
./miniAI train --dataset digits --data
2. Model Load Fails
Error: Could not open IO/models/alpha_brain_png.bin
Causes:
- Model file doesn’t exist.
- Wrong path (missing
IO/prefix or something of the kind).
Solutions:
# Check model exists
ls -la IO/models/
# Train model if missing
./miniAI train --dataset alpha --data
# Use correct path, if passing it
./miniAI test --model IO/models/alpha_brain_png.bin --image test.png
3. Low Accuracy
Cause: Suboptimal hyperparameters.
Solution: Run benchmark to find optimal configuration.
./miniAI benchmark --dataset digits --data --reps 5
# Uses found config automatically in subsequent training/testing
4. Segmentation Fault
Cause: Arena too small for large models.
Solution: Increase arena capacity in source code.
// In command file (e.g., Train.c)
Arena *perm = arenaInit(32 * MB); // Increase from 16 MB
5. NaN in Loss
Cause: Exploding gradients.
Solution:
- Reduce learning rate, or,
- Increase
GRAD_CLIPinAIHeader.h.
Advanced Debugging
To do a more advanced debugging, add debug prints in forward pass, with, for example:
void debugForward(Model *m, Tensor *input) {
for (int i = 0; i < m->count; i++) {
printf("Layer %d:\n", i);
printf(" Z min/max: %.4f / %.4f\n",
minValue(m->layers[i].z),
maxValue(m->layers[i].z));
printf(" A min/max: %.4f / %.4f\n",
minValue(m->layers[i].a),
maxValue(m->layers[i].a));
}
}
Educational Concepts
Feed-Forward Neural Networks
A feed-forward network consists of:
- Input layer: Receives features (image pixels).
- Hidden layers: Intermediate processing.
- Output layer: Produces class probabilities.
Gradient Descent
Training uses Stochastic Gradient Descent (SGD) with:
- Shuffle: Random order of examples in each epoch.
- Mini-batch: One example at a time (kind-of online learning).
- Learning rate decay: Gradual LR reduction for fine convergence.
Regularization
Techniques to prevent overfitting:
- L2 Regularization (Weight Decay)
Loss_total = Loss_CE + lambda * ||W||²Penalizes large weights, favoring simpler models
- Gradient Clipping
if |grad(W)| > threshold: grad(W) ← threshold * sign(grad(W))Prevents gradient explosion
- Data Augmentation
- Random pixel flipping (salt & pepper noise)
- Increases model robustness
Xavier/He Initialization
Smart initialization based on layer size:
Inference Dataflow
Inference Dataflow

void tensorFillXavier(Tensor *t, int inSize) {
float scale = sqrtf(2.0f / (float)inSize);
for (int i = 0; i < t->rows * t->cols; i++)
t->data[i] = (((float)rand() / (float)RAND_MAX) * 2.0f - 1.0f) * scale;
}
Maintains constant activation variance across layers, facilitating training.
Possible Extensions
Future Features
Please, contribute.
- Advanced Architectures
- Convolutional Neural Networks (CNN).
- Dropout layers.
- Batch Normalization.
- Optimizers
- Adam optimizer.
- RMSprop.
- Momentum.
- Data Augmentation
- Rotation.
- Scaling.
- Translation.
- Elastic deformation.
- Visualization
For those of you who are Python masters, which I’m definitely not.- Loss curve plotting.
- Filter visualization.
- Feature t-SNE.
- Dataset Loading
- MNIST loader.
- CIFAR-10 loader.
- CSV/NPY format.
How to Contribute
To add new features:
- Maintain zero-dependency philosophy.
- Use arena allocator for allocations.
- Document functions with comments.
- Add tests in appropriate command (or create a new one, if that is the case (also add usage in help, in that case)).
- Update this README.
See Contributing section below for detailed guidelines.
References and Resources
Fundamental Concepts
- Neural Networks and Deep Learning - Michael Nielsen.
- Deep Learning Book - Goodfellow, Bengio, Courville.
- CS231n: Convolutional Neural Networks (I did not use a CNN, but there were some pretty good ideas here, which I used!).
Implementation Techniques
- Backpropagation Algorithm - Yann LeCun.
- Xavier Initialization - Glorot & Bengio.
- Adam Optimizer - Kingma & Ba (future implementation!).
Regularization
- Dropout - Srivastava et al (shoutout to Toronto Uni colleagues!).
- Batch Normalization - Ioffe & Szegedy.
Technical Notes
Known Limitations
- Scalability: Current system designed for small datasets.
- GPU: No GPU acceleration support (CPU only).
- Datasets: Requires pre-segmented or preprocessed images. If we feed the AI non-segmented or non-preprocessed images, it will have a very hard time recognizing them.
- Precision: Uses float32 (may be limiting for deeper models).
Design Decisions
- Zero Dependencies: Only C stdlib and libm for maximum portability.
- Arena Allocator: Trade-off between flexibility and performance.
- Row-Major: Matrices in row-major for cache locality.
- Hardcoded Activations: ReLU/Softmax hardcoded for simplicity.
- Unified CLI: Single executable with multiple commands for ease of use.
Contributing
Contributions are welcome! This project has automated CI/CD.
Automated Checks
- Build on Linux and macOS
- Run tests
- Check code quality
Templates
For detailed guidelines, see CONTRIBUTING.md.
License
This project is licensed under the MIT License - see the LICENSE file for details.
Author
Nelson Ramos
- GitHub: @nelsonramosua.
- LinkedIn: Nelson Ramos.
Acknowledgments
- stb_image by Sean Barrett - PNG loading.
- Deep learning community for educational resources.
- All (eventual) contributors and testers.
For questions, suggestions or bugs, please open an issue.